微信公众号:OpenCV学堂
关注获取更多计算机视觉与深度学习知识
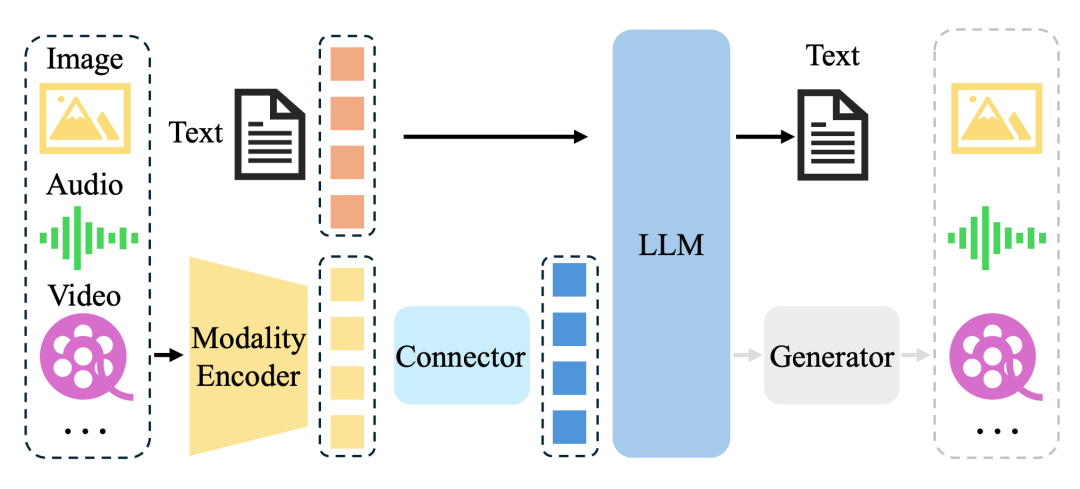
什么是多模态大模型(MLLM)
多模态大模型(MLLM)是一种能同时理解和生成文本、图像、音频、视频等多种信息类型的AI系统。其核心在于通过统一的架构(通常基于强大的大语言模型)整合不同模态的数据,形成一个能够进行跨模态推理与生成的“通用”智能体。

它通常采用“编码-对齐-解码”的技术路径:先用专用编码器将图像等非文本数据转换为特征,与大语言模型的语义空间对齐,最终由模型统一生成回答或内容。例如,用户上传一张图片并提问,MLLM能“看懂”图像并给出文字描述或分析。
目前,世界顶级的AI公司的主流模型已具备此能力,正推动AI向更通用、更贴合人类多感官认知的方向发展。大模型技术已经进入下半场,从纯文本的LLM范式进化到更高级MLLM范式
零样本缺陷检测
零样本工业缺陷检测模型是当前工业AI领域的前沿研究方向,旨在通过多模态大模型的图像与文本提示输入结合,实现感知与认知模型融合,解决传统CNN与YOLO系列模型的监督学习方式在缺陷检测面临的核心痛点:依赖大量缺陷样本、难以应对新缺陷。
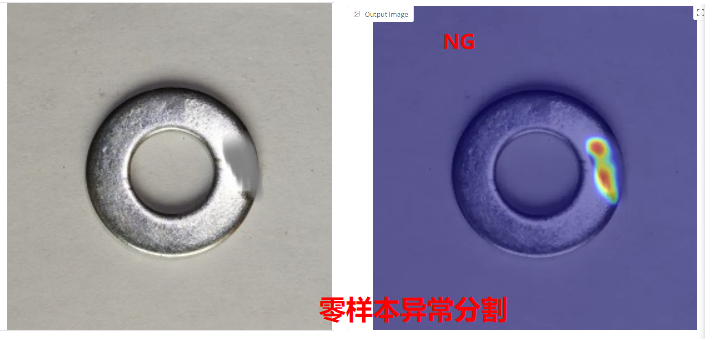





多模态VLM模型工业缺陷检测的优势在于真正意义上的“零样本”,无需针对特定任务训练,灵活度高,可应对开放词汇描述的新缺陷。工业支持急速五分钟换型、四张参考样本准确率可以达到99%。
重磅发布
视觉领域融合文本提示,实现多模态感知决策,构建与应用视觉语言模型(VLM)已成为视觉算法工程师通往未来的关键能力。它们打破了图像的单一维度,让机器能像人类一样,同时理解图像、文本、声音乃至视频的丰富信息。深度解锁创意设计、医疗诊断、自动驾驶、智能制造等领域的革命性应用。

为了更好的帮助大家理解与掌握多模态VLM开发技术,OpenCV学堂通过2025年一年的时间,研发了这套多模态工业零样本缺陷检测课程,帮助大家在2026年更好的起飞。
适合人群
AI算法开发者、机器视觉开发者、深度学习开发者、上位机应用开发者、本科高年级与研究生、科研院所的人工智能算法研究与技术人员。
课程内容
系统化学习Transformer模型注意力机制原理、编码器、解码器设计、理解BERT、GPT3模型架构;掌握VIT、DieT、Swin、RTDERT、RFDETR等主流视觉Transformer模型从训练到部署、深入理解CLIP、DINOv2、DINOv3、SAM2等视觉语言大模型(VLM)结构,掌握基于VLM的图像分类、对象检测、OCR识别、零样本工业异常检测、异常分割、PCA主成分分析、小样本训练、知识蒸馏等主流VLM开发技术、掌握视觉语言模型与多模态模型的全栈开发技术,成为多模态VLM开发工程师。课程内容十章如下:
第一章:神经网络基础001-感知器与MLP基础002-反向传播原理003-人工神经网络模型构建与训练004-图像卷积基本原理005-卷积神经网络基本概念与原理006-卷积神经网络构建与训练第二章:Transformer网络001-注意力机制概述002-自注意力QKV计算003-自注意力矩阵计算004-自注意力代码实现005-多头注意力与代码实现006-掩码注意力机制007-交叉注意力机制008-Transfomer网络六大要素009-Transformer编码器与解码器详解010-Transfomer代码实现与训练第三章:Bert与GPT网络001-BERT模型介绍002-BERT单词预测与上下文相关性分析003-GTP系列模型结构与介绍004-GPT2与GPT3文本生成代码演示第四章:VIT系列网络001-ViT模型结构详解002-ViT模型实现图像分类003-DieT模型与知识蒸馏004-Swin Transformer结构详解005-Swin Transformer迁移学习代码详解第五章:RTDETR与RFDETR系列网络001-RTDETR网络模型详解002-RTDETR自定义数据集训练003-RTDETR模型部署推理004-RFDETR网络模型005-RFDETR自定义数据对象检测训练006-RFDETR模型部署推理第六章:单模态与多模态001-多模态与视觉语言模型概述第七章:CLIP网络与应用001-CLIP网络模型详解002-CLIP逻辑回归图像分类003-CLIP零样本迁移图像分类004-CLIP图像特征提取与相似比对005-CLIP构建以文搜图与以图搜图006-CLIP零样本异常缺陷分类检测007-CLIP零样本异常缺陷分割检测008-CLIP模型微调自定义正样本缺陷分割检测从训练到部署第八章:DINO网络与应用001-DINO系列网络模型详解002-实战DINOv2零样本图分类003-零样本DINOv2与DINOv3特征提取与分割004-基于DINOv2特征的PCA分析005-DINOv2零样本异常缺陷检测第九章:SAM网络与应用001-SAM1到SAM3网络模型结构详解002-SAM2实例分割与跟踪第十章:VLM系列模型与应用001-VML模型概述与典型架构002-QWEN-VL实现图像查询OCR识别003-QWEN-VL零样本对象检测004-InternVL实现图像内容精准查询005-总结与福利
报名方式
加小助手微信,获取专属课程资料

现在下单,拼团优惠
原价:1199
拼团:999

未来的AI,必将是感知与认知交融的“全能思考者”。率先掌握多模态与视觉语言模型(VLM)这项技术,就是掌握了塑造新产业、定义缺陷检测新规则的核心主动权。2026年正是拥抱多模态,解锁零样本缺陷检测最佳起点,扫码下单,加小助手微信进群跟小伙伴一起努力吧。
