
黄仁勋(NVIDIA CEO)近两年都很热衷于解答,在摩尔定律已然不行,AI模型规模又以10倍速增长的情况下,NVIDIA的芯片到底如何满足AI技术发展需求这一问题。比如说前年发布Blackwell之时,他说Blackwell相比Hopper性能提升30倍——对半导体芯片而言,这样的数字是不现实的;而30x的逻辑,我们也特别撰文探讨过。
今年CES消费电子展上,他又在发布会上提到Vera Rubin NVL72这样一个系统,总的晶体管数量是220万亿,相较上代超节点增长了1.7倍;但标称的推理与训练(NVFP4)性能分别提升5倍和3.5倍。即便从加速器的角度来看,这真的科学吗?
黄仁勋在今年CES主题演讲中反复在提的一个高频词是“co-design”(协同设计)——不是说NVIDIA与其他企业协同做设计,而是NVIDIA的不同芯片之间做co-design。因为“extreme co-design”(极致的协同设计)的存在,才让1.7倍晶体管总量增长,达成了5倍、3.5倍的AI性能提升。
那究竟是哪些芯片之间做了协同设计呢?在发布会的后30分钟里,老黄花了较大篇幅介绍NVIDIA现如今的“6颗芯片”。关注NVIDIA或者电子工程专辑这些年对NVIDIA报道的读者对这6颗芯片应该不会陌生,它们分别是:CPU、GPU、NIC芯片、DPU、用于scale-up的NVLink Switch交换芯片、用于scale-out的CPO(共封装光学)以太网交换芯片。
但有所不同的是,这6个类型的芯片新品全部用在了Vera Rubin NVL72机柜里头:以6颗芯片、总计220万晶体管,满足对于AI技术近乎疯狂的算力需求增长。

要不说老黄是营销鬼才呢,他说:“我们公司原本有个规则,每代新产品中不应该有超过2款芯片迭代”,但考虑到“摩尔定律大幅放缓”,“晶体管每年增长的数量,跟不上AI模型规模的10倍增速,跟不上每年生成的token数5倍增速,跟不上因此所需的成本降低速度”......所以NVIDIA做出了一个违背祖宗的决定,“横跨所有芯片、整个技术栈,做出创新、进行极致的协同设计”,“在这一代产品中,我们没有选择,唯有重新设计每颗芯片”。
这篇文章,我们就详细谈谈这6颗芯片,及其构成的Vera Rubin NVL72系统;并尝试探讨1.7倍晶体管数量增长,如何达成5倍、3.5倍的训练与推理性能提升——当然,只是高抽象层级。
6颗芯片、220万亿晶体管的超节点
“超节点”这个词的出处有些不可考,它似乎是在GB200 NVL72系统诞生以后爆火的。但这个词的诞生应当早于本世代AI浪潮。可能在不同AI芯片企业及行业媒体的上下文中,这个词的含义也都有不同。NVIDIA官方从未用过“超节点”或SuperNode一词(但有在使用SuperPod这个词)。
不过可以明确的是,在NVIDIA的技术与产品语境中,国内媒体提的“超节点”特指一个NVLink域,或者所谓的高带宽域(high-bandwidth domain)。一个GB200 NVL72机柜就是一个超节点——72颗Blackwell芯片位于同一个NVLink高带宽域内。而本次NVIDIA发布的Vera Rubin NVL72则是对GB200 NVL72的迭代,自然也是超节点。
Vera是CPU的代号,Rubin是GPU的代号,NVL是指NVLink互连,72则表示整个域内有72颗Rubin芯片。值得一提的是,去年GTC上,老黄预告过这一代产品会叫Vera Rubin NVL144——后面这个数字指的是GPU die的数量,因为一个Rubin芯片封装内有两片die,所以72颗GPU,也就是144颗die。
现在看来,NVIDIA是改变主意了,沿用了上一代Grace Blackwell NVL72的命名规则。老黄说Vera Rubin当前已经进入量产(full production)阶段;媒体会上是说今年下半年开始上量。首批部署Vera Rubin实例的客户主要是CSP这样的云合作伙伴(如Microsoft Azure, CoreWeave)。
实际上,NVIDIA大约是在一年半前开始出货GB200的,目前GB300进入到全面上量阶段。就企业市场角度来看,NVIDIA这个迭代速度还是相当之快。
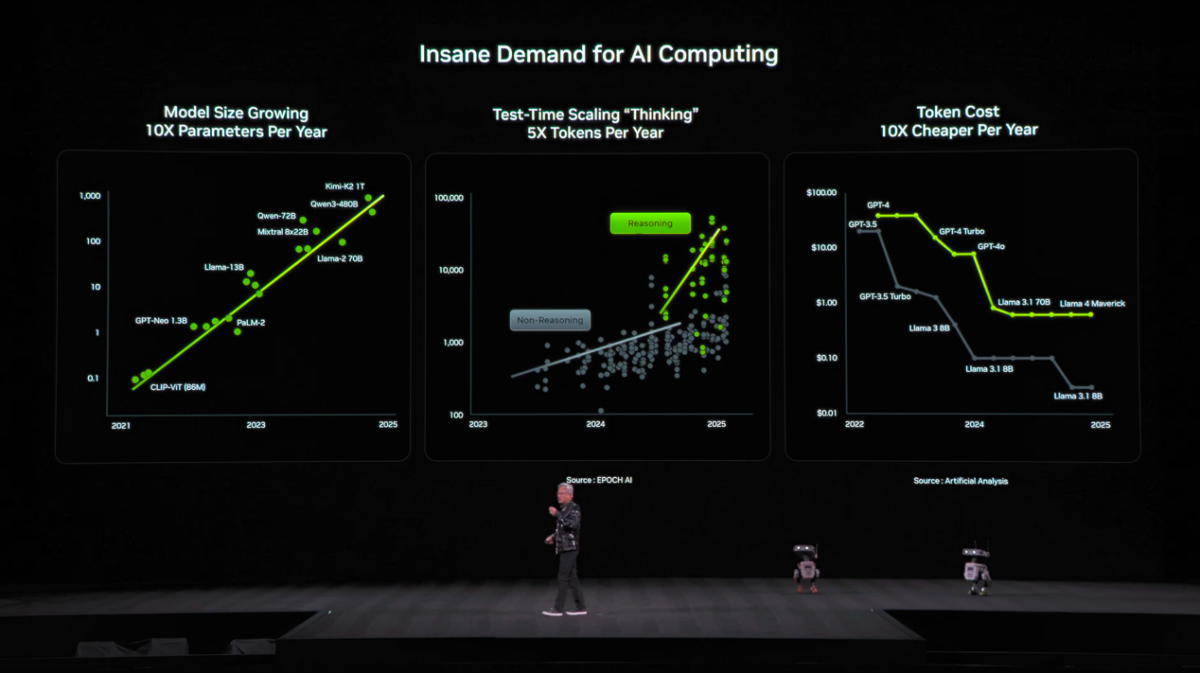
黄仁勋说,因为AI模型每年规模增长10倍,每年单位token的成本降低10倍(数据来源:Artificial Analysis),以及因为agentic AI和推理思考模型(reasoning model)的普及导致平均每年生成的token数以5倍速增长(数据来源:EPOCH AI),“所以我们决定必须每年都推升计算”。
这套NVLink高速互连域内最关键的核心构成,是来自NVIDIA的5颗芯片:Vera CPU, Rubin GPU, ConnectX-9 NIC芯片, BlueField-4 DPU, NVLink 6 Switch交换芯片。除了NVLink域内的这5颗芯片,还有一颗用于scale-out的芯片就是去年特别火的CPO(共封装光学)交换芯片Spectrum-X Ethernet。它们共同构成了NVIDIA这次宣传中谈到的“6颗芯片”。
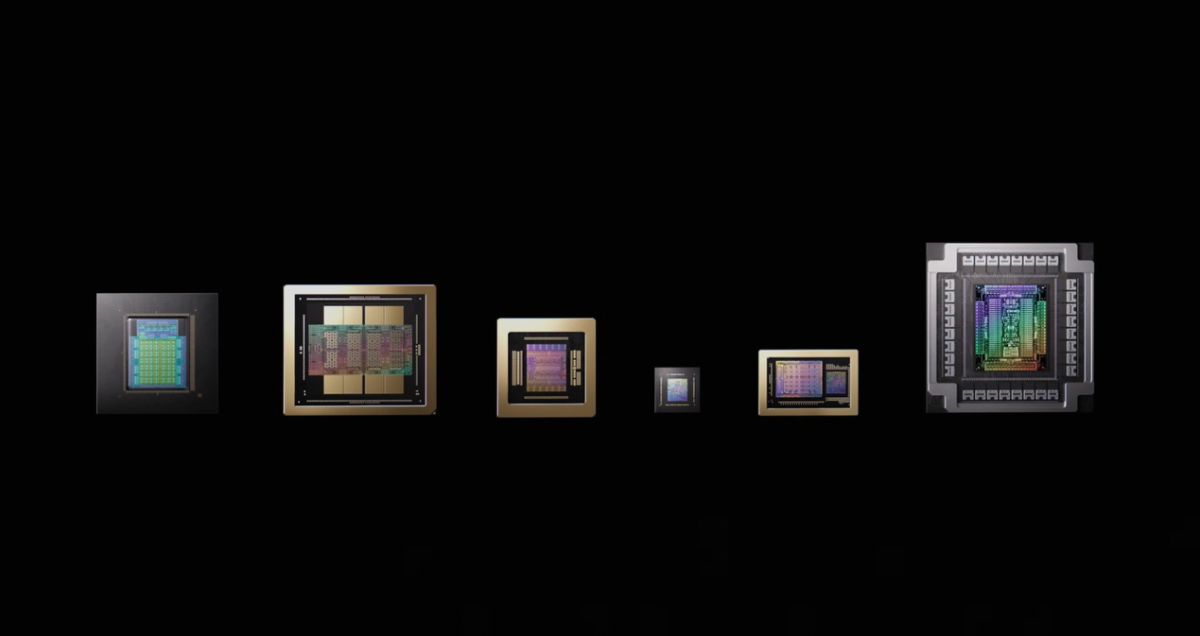
传说中的6颗芯片,从左到右依次是CPU, GPU, NIC, DPU, NVLink Switch交换芯片, Ethernet CPO交换芯片…没想到封装个头最大的还是CPO交换芯片...
整个Vera Rubin NVL72系统标称的算力数字包括NVFP4推理理论峰值算力3.6 ExaFLOPS(5倍于Blackwell)、NVFP4训练理论峰值算力2.5 ExaFLOPS(3.5倍)、LPDDR5X内存容量54 TB(3倍)、HBM容量20.7 TB(1.5倍)、HBM4带宽1.6 PB/s(2.8倍)、scale-up带宽260 TB/s(2倍)。
“通过极致协同设计,6颗芯片构成的系统,就像一颗芯片一样工作。”计量单位上,除了6颗芯片、220万亿晶体管这种说法,实际上整个机柜有18个计算槽、9个NVLink交换槽,重量约2.5吨。它的确称得上当代AI超节点的巅峰之作。在CPU, GPU芯片算力之外,着眼存储、互连,加上软件效率的提升,也是全栈及整个设备实现数倍性能提升的不二法门。
有关Vera Rubin NVL72系统,黄仁勋在演讲中说基于这套设计,构建行业标准系统,让供应链的所有参与者都能够对系统中的组件进行标准化设计制造。此例中,NVIDIA自己的模块化服务器参考架构MGX系统大约由80000个不同的组件构成。“如果我们每年都去改变,将会是巨大的浪费”。而标准化得以让OEM/ODM企业更好地去造这套系统。

值得一提的是,黄仁勋还提到NVL72系统的的液冷散热可以用45℃的“热水”,如此一来也就不需要制冷机了。我们了解了一下45℃液冷散热的基本原理:因为NVL72使用直接接触芯片的冷板来做热交换,芯片本身的结温可以很高,45℃的进水、55-60℃的出水,有热梯度、流速足够时,也能做到有效散热。这一点代表的,大概也是新版NVL72在系统层面的能效提升。
CPU与GPU:5倍算力增长怎么做到的?
老黄说,这6颗芯片,每颗都是值得单独开发布会的,因为“每个都是完全的革新、是同类芯片中最好的”。在这6颗芯片中,提供算力的主力自然就是Vera CPU和Rubin GPU了。

其中Vera CPU总共88个Olympus核心,176线程。NVIDIA称其为“Spatial Multi-Threading”(空间多线程)。有外媒报道说,这种空间多线程不同于传统的同时多线程,并非在共享管线中做线程同时执行,而是一种所谓的“thread-to-port分布”,线程映射到不同的内部端口(更像加速器的多线程?)。
猜测这可能与Vera和传统的通用CPU设计目标不同有关,其主要职能就在于协同GPU、调度KV cache、压缩和解压数据、组织NVLink流量、跑AI runtime代码等,明确的负载具有更高的可预测性、更低的管线冲突,空间多线程也因此更能提升效率。用老黄的话来说,“Vera的多线程特性是设计好的,176个线程的每一个都达成了完整的性能”。
其他有关Vera的参数还包括2270亿晶体管,1.8 TB/s NVLink-C2C, 1.5 TB系统内存, 1.2 TB/s LPDDR5X带宽。发布会的视频介绍中提到,相比前代(Grace)实现了性能的翻倍。

此次芯片迭代的重头戏自然是Rubin GPU了。NVIDIA介绍Rubin的第一句话就是:Vera和Rubin是从一开始就做“协同设计”的,“双向地、一致地,共享数据更快、延迟更低”。老黄也是在这里提到了所谓的“极致协同设计”。
Rubin的晶体管数量为3360亿个,是Blackwell的1.6倍;标称的理论算力包括NVFP4推理50 PetaFLOPS(5倍于Blackwell,虽然这个倍数是部分值得商榷的)、训练35 PetaFLOPS(3.5倍)、HBM4带宽22 TB/s(2.8倍)、每GPU的NVLink带宽3.6 TB/s(2倍)。这么看来,NVL72系统层面的AI性能提升倍率,基本与GPU的性能提升相当。
这里有个关键,是GPU之中所谓NVFP4 Tensor core的存在。NVIDIA在媒体会上提到第3代Transformer引擎实现了向前兼容,而且增加了自适应硬件(adaptive hardware)来推升NVFP4的性能。此前Blackwell宣传中标称的数据,包括NVIDIA给到的5x, 3.5x对比数据都是基于Blackwell跑FP4和FP8的(实际上有研究提到NVFP4本身对于Blackwell的LLM推理也有显著的效率提升)。
黄仁勋也在发布会上着重提到了NVFP4,“并不只是个4bit浮点数”,“全新的处理单元能够理解如何动态、适应性地调整精度和结构,来处理Transformer不同层级的问题。如此一来,在可以损失精度的场景下获得更高吞吐,而在有需要时回到更高的精度。”他将NVFP4形容为创举(groundbreaking work),“如果将来行业希望这种格式和结构能够成为行业标准,我也不会感到意外”。NVIDIA也已经就NVFP4发布了paper,有兴趣的同学可以去看一看。


Vera与Rubin的组合,依旧是每1颗Vera搭配2颗Rubin,实现100 PetaFLOPS算力。介绍中提到Vera Rubin计算板上总共有17000个组件;且这样一个计算节点(2个Vera CPU,4个Rubin GPU)没有线缆、没有风扇、没有软管,完全液冷。据说在整个MGX参考结构的革新之下,以往至少需要2小时组装起来的计算节点,现在只需要5分钟。
互连组合:NIC、DPU、NVLink Switch、CPO交换芯片
算力之外的第二个大问题就是网络互连networking了:现在我们常说,NVIDIA生态护城河并不单纯在其软件,也在于算力芯片之外、这些配套networking基础设施的高效性,对其他GPU和AI芯片企业而言在技术上给到了相当大的压迫感:超节点构建本身就有挑战,更不用谈万卡、十万卡集群的构建。
作为Vera Rubin NVL72系统内的计算节点,其上肯定不单有CPU和GPU。其中的关键构成还有8个ConnectX-9 NIC,以及1个BlueField-4 DPU。电子工程专辑过往针对NVIDIA的报道文章很少谈NIC和DPU。

从本文的行文逻辑来看,理论上应该先介绍scale-up的NVLink Switch的,但NVIDIA的6颗芯片一字排开的那张图上,CPU和GPU之后就是NIC,所以这里也先谈ConnectX-9(而且NIC和DPU毕竟是位于计算节点之中的)。所谓的ConnectX-9 Spectrum-X SuperNIC用于做机架间的互连实现——是东西向流量传输、scale-out的基本组成部分。
此前NVIDIA就宣传说,ConnectX-8就是为跑AI的Ethernet设计的——因为AI负载的Ethernet流量要求很低的延迟,瞬间突发流量和传统Ethernet也不是一个量级,所以“Spectrum-X就是AI Ethernet”。据说这次的ConnectX-9 NIC芯片也与Vera CPU做了协同设计。

ConnectX-9 NIC芯片有230亿晶体管;200 PAM4 SerDes实现800 Gb/s的以太网传输;可编程RDMA与DPA(Data Path Accelerator,一个加速数据包与IO处理负载的嵌入子系统,支持开发者在其上跑代码,完全绕过host CPU);以及安全方面的线速加密、Security Enclave安全隔离与Attestation可信证明,并通过CNSA与FIPS认证。
有关ConnectX-9的重要性,黄仁勋是这么说的:如果你有个GW(GigaWatt)级别的数据中心,需要投入500亿美元;如果说networking组件能让你多挤出10%的性能,那也相当于50亿美元了;而Spectrum-X能提供25%更高的吞吐。


随后是控制面的BlueField-4 DPU——作为一种给host CPU减负的数据处理器,这颗芯片总计1260亿个晶体管,主体部分是64个Grace CPU核心搭配ConnectX-9(曾经的超算CPU如此奢侈地用在了DPU上...),相较BlueField-3实现了2倍networking能力、6倍计算、3倍内存带宽的提升。有关DPU的具体职能,在此就不做过多解释了。
简单来说,是“面向南北向流量,对大量虚拟化、安全、networking软件做offload”。“BlueField-4让我们能够构建起非常大型的数据中心,并对不同的部分做隔离——不同的用户就能使用不同的部分,确保更出色的虚拟化实现。”


然后就是真正的、超节点域内的高速实现,用于scale-up的NVLink Switch交换芯片了。Vera Rubin NVL72系统内的NVLink交换设备内总共有4颗第六代NVLink Switch交换芯片,每颗1080亿晶体管,“每个都用上了历史上最快的SerDes(400G)”;面向每颗GPU的All-to-All带宽为3.6 TB/s。
“在同一时间内,每颗GPU要和其他每颗GPU进行对话。而NVLink Switch交换设备要搬运相当于全球互联网数据流量的2x之多的数据,240 TB/s,是每颗GPU之间协同工作的保证。”



实现万卡集群、scale-out的最后一个重头戏,毫无疑问就是Spectrum-X Ethernet CPO交换芯片了。CPO共封装光学也被电子工程专辑和国际电子商情同时列为2026年的市场与技术趋势之一。这颗芯片及对应的交换机是去年GTC上发布的:当时的Spectrum-X Photonics交换机上市计划就是在2026年。
从NVIDIA的官方动画来看,Spectrum-X Photonics交换机实际上并不在Vera Rubin NVL72机架上——毕竟它是用于NVLink域外的数据交换的。不过当涉及千卡万卡的AI集群或数据中心之时,这台交换机及其中的CPO交换芯片自然也是关键。
这颗CPO芯片将进行光电转换的硅光引擎以chiplet的方式与交换芯片封装在了一起,采用台积电COUPE封装技术。这么做有利于提升能效、互连韧性,同时据说也加快了部署速度。这应该也是市面上第一款采用COUPE、量产的光电共封交换芯片。
这颗芯片的晶体管数量来到了恐怖的3520亿个,比Rubin还多,可能和周围配了那么多chiplet硅光引擎有关,也才让其个头在6颗芯片中显得最大。具体参数包括有512个200Gbps Ethernet口支持(或128个800Gbps口)。

其实在谈到Spectrum-X交换机的时候,老黄也顺带提了一嘴Infiniband——他说Infiniband技术本身很不错,但软件栈、可管理性对于不熟悉它的人来说会很陌生,“所以我们决定第一时间投入到Ethernet市场。”“下一代Spectrum-X也会持续这样的传统。”未知NVIDIA对Infiniband的态度未来会不会有所转变。
存储:接入一个新的“长期记忆”层级
以上就是6颗芯片及其构成的NVL72系统的全部信息了。这几颗芯片主要涉及的就是计算(computing)与互连(networking),不过这不是全部。一般现在我们谈AI算力的系统效率,总是从三个角度切入的:计算、互连、存储。
NVIDIA本身不做存储芯片,但过去两年NVIDIA越来越多地涉足存储技术——毕竟它也是当代影响AI计算效率的关键因素之一。去年GTC上,NVIDIA宣布“基于语义的存储系统”(semantics-based storage system)将会是未来的企业存储。当时NVIDIA找来了包括Dell, HPE, IBM, PureStorage等在内的企业合作。
今年CES之上,NVIDIA又提到:由于模型规模在增大,推理的上下文长度在增大,还相关用户及会话的更多并行需求,这些都对存储提出了要求,尤其对话过程中更长的上下文成为了瓶颈。“AI需要创建临时记忆,也就是KV cache;这些记忆存储在HBM内存之中。”黄仁勋解释说,“GPU需要读入整个模型、整个记忆(KV cache),来生成1个token;然后再将该token放回到KV cache中,再进行下一轮的token生成,循环往复...”
“如果和AI进行长篇对话,上下文记忆大幅增加。”“我们当然希望AI成为我们的生活伴侣,记住每一次对话。”“加上很多人一起用AI数据中心资源...”“这些上下文记忆增加,HBM再大也不够”。与此同时,海量的token生成需求、KV cache搬来搬去致大量网络流量压力,对于AI实验室、云服务供应商等角色而言都是痛点。

媒体会上,NVIDIA HPC与AI基础设施解决方案资深总监Dion Harris说,agentic AI时代的性能瓶颈正从计算转向上下文管理。所以NVIDIA这次提出的方案是构建一个所谓“Context Memory Storage Platform”(上下文记忆存储平台)的平台,并“让新的处理器(BlueField-4)去跑整个KV cache上下文内存管理系统,让它和机架的其他部分非常靠近”。
从黄仁勋在发布会上所指的位置来看,下面这张图NVL72机架右边的部分,就是“上下文内存”,每个设备内有4颗BlueField-4芯片,提供150TB的“上下文内存”。“这样的后备存储,享有东西向流量相同的200Gbps速率,横跨整个计算节点fabric,就能获得额外16TB的内存。”

Dion将该平台形容为针对推理优化的、内存新层级(new tier of memory)。“存储不应该是低优先级的问题,而应当与网络协同设计,以0开销的方式在节点之间实现上下文的搬运。”“这是个AI原生的存储架构,建立在BlueField-4和Spectrum-X Ethernet基础之上,做KV cache的存储;并与NVIDIA Dynamo和NIXL紧耦合。”
该平台的拓扑结构不明,不过从媒体会上给出的示意图来看,这就是个专门的存储节点——主控是BlueField-4,搭配一堆SSD;再藉由Spectrum-X Ethernet交换机,与计算节点做互连;该存储节点位于计算节点和网络存储(networked storage)之间——如果说HBM是G1级,系统DRAM是G2级,本地SSD是G3级,冷数据共享对象与文件存储是G4级,那么这个推理上下文内存存储平台就是G3.5级。
感兴趣的同学可以去看看NVIDIA的开发者博客文章。博客文章将这个新层级形容为“AI基础设施pod的agentic长期记忆”,不仅对于多agent可同时放置共享上下文,而且与GPU和主内存足够近。具体的效果是推理性能5倍提升(相比用传统网络存储来做推理上下文,该平台的每秒token生成数是其5倍),以及5倍的Perf/$和能效提升。
换句话说就是更高的吞吐、更低的延迟,“适用于多轮对话、RAG、agentic AI多步推理(reasoning)等负载”。Dion在答记者问时提了一句,最直观效果可能是首token生成速度(TTFT)有机会提升20倍。
这套方案是被NVIDIA作为“极致协同设计”典范对待的,因为也“不能孤立看待存储”。当然接入这样一个新的层级,肯定需要存储领域的合作伙伴参与(如NetApp, VAST等),“客户会去做集成,作为完整整合AI基础设施的一部分”,算是真正的“协同设计”了。
“极致协同设计”的价值
黄仁勋在总结中提到Vera Rubin NVL72的四个关键特性。其一是整个系统实现了2x的能效提升,“虽然功耗是过去的2倍,但算力收益却好几倍”;其二,整个系统是confidential computing safe机密计算安全的(主要应该是Vera实现了这一点,上代Blackwell仅在x86平台上做到)——Dion说这代达成“第3代机密计算”实现了首个机架级(rack-scale)TEE(可信执行环境),跨整个NVLink域做到数据安全,保护专用模型、训练数据、推理负载等;
其三听起来是AllReduce引入的供电突增、电流尖峰问题,藉由“power smoothing”机架级功率调度,而不需要再预留多25%的供电预算;其四自然就是性能、效率的具体提升数字了:
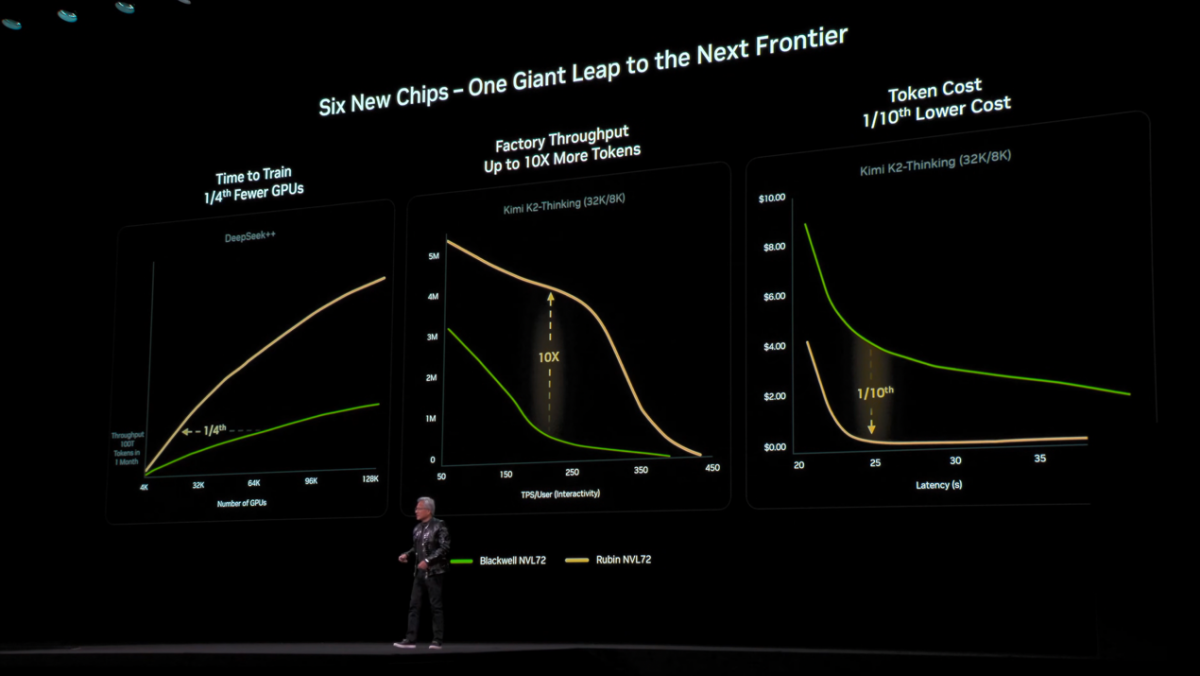
这张图中的绿色和黄色曲线分别代表Blackwell NVL72和Rubin NVL72。第一张图表示AI模型训练,这里的“DeepSeek++”指的是用100万亿个token作为训练数据,训练10万亿参数的模型——这是NVIDIA预想中未来的前沿模型,一定训练时间下(1个月),后者仅需要前者1/4的GPU数量即可完成。
而对AI工厂的吞吐(横轴每个用户的token/s数字;纵轴应该是整体的每秒token数)而言——这个对比样式也是去年黄仁勋发布Blackwell时最后展示的,他说曲线覆盖的面积可代表企业的营收;基于Kimi-K2 Thinking模型,Rubin NVL72达成了10倍的吞吐提升。
有关这一点,值得一提的是,媒体会上NVIDIA有强调如今MoE模型的流行及其更高的智能水平(就是以Kimi-K2 Thinking举例的)——以更高的效率去跑更大的模型成为可能——而Vera CPU和Rubin GPU的提升(Vera格外擅长编排、路由、调度KV cache和上下文,而Rubin在算力和内存带宽方面提升不少),加上NVLink 6 Switch强化EP专家并行所需的All-to-All GPU互连,令这代产品特别适用于MoE模型负载。
所以最后一张曲线图就是Rubin NVL72仅需Blackwell NVL72大约1/10的单位token成本。

如果说相较Grace Hopper,GB NVL72的性能提升主打的是系统层面(尤其NVLink域的扩张,以及互连加强)的革新,那么Vera Rubin NVL72的性能提升主打的就是NVIDIA在各种场合反复在提的“协同设计”,以及6颗芯片的全面翻新。这是1.7倍晶体管数量增长,带来5倍性能提升的核心——包括对NVFP4的强调、KV cache存储新层级的引入,也可以归在“协同设计”之内。
还有一个部分是本文没有提的,就是软件:包括黄仁勋这次花了大量篇幅去谈的NVIDIA是开源开放模型(比如这次面向汽车的reasoning VLA模型Alpamayo)、开放数据集生态中的佼佼者,同时也为开发者打造了各种各样的模型工具与框架、Blueprint参考工作流,还有每次都要提的在AI全栈各层级的努力——毕竟这些才是NVIDIA实现AI生态黏性的关键。
AI的发展速度到2026年的今天,仍然是超出了我们预期的。世界从感知型AI,走向生成式AI、代理式AI(agentic AI),进化到与物理世界交互的、以汽车和机器人为代表的物理AI(physical AI);AI计算的侧重也由预训练、后训练(post-training)转向了推理(test-time)...
一个挺让人感触的事是,今年CES上黄仁勋列举的合作伙伴包括了Synopsys、Cadence,特别提到这些EDA企业原本是为NVIDIA赋能的上游企业;而随着AI技术的发展,NVIDIA现在也能为它们服务,比如CUDA-X融入到了Cadence的模拟仿真和求解器之中,尤其让AI Physics在电子或系统设计工具中发挥作用。
“最初从他们这样的企业出发,我们现在也有机会回去帮助他们来做出革新。”这就是AI技术魅力的体现了。

