(本文编译自Semiconductor Engineering)
业界曾普遍认为,下一代高带宽内存HBM4需要借助混合键合技术,才能实现16层内存堆叠。然而JEDEC的一项新规让该技术在这一代产品中失去了必要性,但这仅仅是推迟应用,并非彻底取消。
在数据中心人工智能领域,尤其是AI训练环节,HBM的需求一直居高不下。数据传输是能耗的主要来源,相比各类标准DDR内存,HBM能够以更快、更高效的方式传输海量数据。
“我们看到市场对各类内存的需求都很旺盛,无论是非易失性内存还是易失性内存,”联电高级封装总监Pax Wang表示,“但在人工智能时代,HBM是最重要的。”
HBM技术的核心是将多个内存芯片垂直堆叠。“目前HBM已实现12层堆叠,正向16层堆叠发展,”Brewer Science封装解决方案业务开发工程师Hamed Gholami Derami表示。
提升内存容量的路径有两条:一是增加堆叠层数;二是提升单个芯片的存储单元密度。直到最近,JEDEC规定堆叠层数最大高度为720µm,即使各类组件的高度都在不断缩减,这个高度仍然不足以支撑16层堆叠。“为了适应高度限制,芯片厚度(当前已降至30-50微米)、凸点高度、芯片间距以及硅通孔(TSV)节距都在持续缩小,”Derami表示。
TSV间距节距属于水平维度参数,看似与芯片堆叠的垂直厚度并无关联,但实际上节距大小会直接影响凸点高度。“TSV间距和凸点高度直接相关,”Derami补充道,“间距越小,凸点也越小。”
同时,作为衡量性能的核心指标,内存总带宽的提升既可以依靠拓宽接口位宽,也能通过提高单引脚的信号传输速率来实现。HBM4不仅拓宽了接口位宽,还将通道数量增加了一倍。其单引脚信号传输速率也高于HBM3,但略逊于HBM3E。
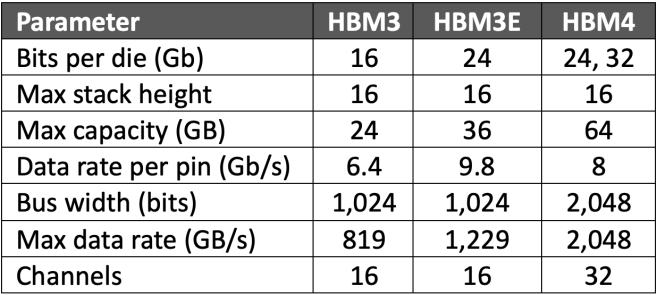
表1:HBM4与HBM3和HBM3E的比较。
(图源:网络)
更宽的接口带来了新的挑战,即需要在大致相同的空间内布置更多引脚。过去,微凸点的节距通常在40微米左右,而到了HBM4,这一节距将缩小至10微米左右。如何实现芯片堆叠中焊盘的键合连接,成为了亟待解决的核心问题。
混合键合曾是规划中的解决方案
“目前,采用模塑底部填充的回流焊(MR)和使用非导电薄膜的热压键合(TCB)是主要的芯片堆叠组装方法,”日月光集团工程和技术推广总监Vikas Gupta表示。
此前,业界一直将混合键合视为降低堆叠高度的理想方案。即使每枚芯片的厚度保持不变,取消微凸点也能缩小芯片层间间距,从而缩短堆叠高度。
yieldWerx首席执行官 Aftkhar Aslam表示:“目前堆叠高度已超过12至16层,这得益于混合键合和晶圆减薄技术的进步。”
“随着HBM规格和性能要求不断突破互连和组装工艺的极限,混合键合提供了一种无凸点的3D堆叠组装方案,”日月光的Gupta表示。
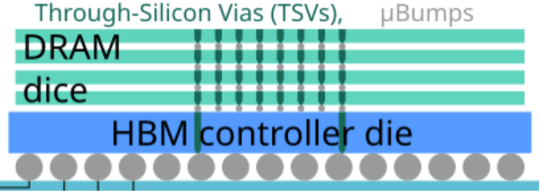
图1:通用HBM结构。
(图源:改编自网络)
混合键合是一种成本高昂的工艺,还需配套全新的设备。率先采用该技术的产品,其单封装成本会更高(但考虑到更高的容量,单位比特成本未必会增加)。
该工艺也给其他方面也带来了挑战,例如测试。对于像由十余个芯片堆叠而成的内存这类高价值产品,必须保证高良率。任何一个芯片出现无法修复的缺陷都可能导致整个堆叠模组报废。因此,只组装已知合格的芯片是提高良率的重要途径。
联电的Wang表示:“良率将是最大的问题。使用微凸点技术,我们可以在焊接微凸点之前测试存储层,但如果改用混合键合技术,测试流程将变得非常困难。”
键合前测试听起来似乎理所当然,但实际情况却因两方面原因而变得复杂。首先,混合键合需要焊盘表面洁净无瑕,而测试探针可能会损坏焊盘或引入颗粒。此外,窄间距焊盘本身也带来了挑战。
第二个挑战是,代工厂通常习惯于将完整的芯片产品运送到OSAT工厂进行测试。但有些代工厂现在会自行组装芯片堆叠。如此一来,代工厂就无需先把芯片送到封测厂测试、再运回本厂进行堆叠,而是需要自行配备测试设备,先完成芯片堆叠,再将完整的堆叠模组交付给封测厂进行封装。
混合键合也给制程中检测和监控带来了挑战。“材料创新至关重要,例如低翘曲基板、超平坦介电层和高性能底部填充材料,同时制程监控也同样不可或缺,”Aslam表示,“目前的检测技术包括光学干涉测量、声学显微镜和用于检测微孔和错位的在线空隙检测。在良率管理方面,相关工具能够进行垂直谱系分析,追溯堆叠中每个存储芯片的晶圆批次、老化测试历史和键合对准参数。通过将HBM堆叠中每一层的测试数据与组装和工艺计量数据关联起来,工程师可以精准定位各类缺陷的成因,包括混合键合对准偏差、TSV电阻漂移或是材料分层等问题,从而将传统工艺中难以把控的3D封装‘盲区’,转化为一个可监测、可追溯的工艺窗口。”
高度限值调整提供缓冲空间
JEDEC将模块高度限制从720µm修改为775µm,这为HBM4沿用微凸点键合技术提供了足够的空间。然而,HBM5及其后续产品预计将采用混合键合技术。
Wang表示:“混合键合技术可以减小焊料互连的厚度,因此已被列入HBM的发展路线图。但由于今年年初JEDEC标准的修订,混合键合技术的应用有所延迟。待到实现18层或20层堆叠结构时——例如HBM4E——混合键合技术有望迎来规模化应用的契机。”
即便采用微凸点技术,HBM4相比前代产品,不仅存储容量与带宽实现跃升,单位比特能耗预计还能降低30%至40%,能效表现大幅提升。“与当前的微凸点方案相比,混合键合技术的单位比特能耗还能再降低一个数量级,”Gupta表示。
HBM4预计还会带来两项与逻辑相关的变化。第一项变化涉及堆栈的基础芯片(也称为逻辑芯片)。该芯片包含运行堆栈所需的所有逻辑电路,也是外部芯片上的内存控制器与之通信的核心枢纽。但在此之前,基底芯片的设计基本趋于标准化,所有出厂产品均采用同款方案。
随着HBM4的推出,企业预计将定制基础芯片,以便更好地使堆栈行为与特定应用相匹配。面向通用市场的标准版本基础芯片仍会持续供应,但部分头部企业(如AMD与英伟达)计划在基底芯片中集成更丰富的功能,借此分担处理器的部分运算负载。
Gupta表示:“定制芯片的特性将随着整体计算架构的发展而不断演进。这种演进将直接影响功耗、高效供电需求以及相关的散热管理方案设计。”
HBM4还将包含一项旨在帮助抵御行锤攻击的新型内存功能。这项名为定向刷新管理(DRFM)的功能有助于刷新可能遭受行锤攻击的内存行。此外,HBM4还将提升可靠性、可用性和可维护性(RAS)特性。
未来需要新的设备和材料
展望未来,业界将继续努力构建更高层数、更快速率的堆叠结构。但在缩小信号间距的同时减薄存储层厚度,必然需要更精密的设备和更好的材料。
“无论是MR还是TCB工艺,都需要更好、更精确的芯片贴装设备,以及改进的芯片间键合和芯片与晶圆键合设备,”Derami表示。
即使采用混合键合技术,MR和TCB键合仍保有一席之地。“HBM中并非所有互连都会采用混合键合,”Derami表示,“各企业正在探索一种解决方案,即DRAM芯片面对面进行混合键合,再将这些键合好的芯片对以背靠背的形式,借助微凸点技术完成堆叠。这似乎是一种权宜之计,因为使用混合键合技术堆叠所有DRAM芯片存在困难,因此在这些集成方案中,仍将使用MR和TCB键合技术。”
晶圆减薄工艺也带来了新的挑战。“随着HBM架构向更多堆叠层数、更精细互连间距演进,要实现超薄芯片的均匀平坦化,同时保障堆栈的热稳定性——尤其是在混合键合方案中——难度正不断攀升,”Derami指出,这些材料需要具备热稳定性才能经受住整个工艺流程。
HBM4E版本预计将于2027年左右投产,紧跟计划2026年量产的HBM4的步伐。各公司已公布各自的目标,其中三星的目标是单引脚传输速度超过13 Gb/s,总带宽达到3.25 TB/s,能效也将得到提升。
限制混合键合技术应用的另一个因素是焊盘间距。现有技术适用于间距小至约10µm的焊盘,因此在该间距下使用混合键合技术在经济上并不划算。HBM4的焊盘间距为10 µm,这也导致了混合键合技术的延迟应用。
END
